Lenmus Hacking Guide
Usually, all learning takes place through repetition. When a new piece of information is presented, human memory tends to forget it if it is not recalled in a certain time period. But if that piece of information is presented again, before being totally forgotten, the memory strengthens and the retention period became greater. I read somewhere that 48 hours after a study session, we have generally forgotten 75% of the presented material. This is one of the key points of the ‘spaced repetition’ method: each time we review a piece of information, our memory becomes stronger and we remember it for longer.
In the days before computers, it was a common practice to write the facts to learn on a set of cards (called flashcards), look at each card in turn, think of the answer, then turn the card over, and take the next card. But, constantly reviewing everything is not an optimal method, and there were no guidelines for deciding when to next review the cards: the next day? Every day for a week? Once a week every month?. Another problem of this method is that easy questions end up being repeated just as often as difficult ones, which means either you’re not reviewing the difficult questions enough, or you’re reviewing the easy ones too often. In any case, your time or memory suffers.
In 1972, a German science journalist named Sebastian Leitner wrote the book “How to learn to learn”, a practical manual on the psychology of learning, that became a bestseller and popularized a new and simple method of studying flashcards. In the Leitner method (also known as spaced repetition learning technique or flashcards method), a box is divided up into a bunch of compartments. Each compartment represents a different level of knowledge. Initially, all cards are in compartment 1. When you remember a card correctly you move it to the next compartment. If you forget, you move it back to the start.

Figure: In the Leitner system, correctly answered cards are advanced to the next, less frequent box, while incorrectly answered cards return to the first box (picture taken from Wikipedia at http://en.wikipedia.org/wiki/Leitner_system. Available under the Creative Commons CC0 1.0 Universal Public Domain Dedication).
The advantage of this method is that you can focus on the flashcards that you have problems to remember, which remain in the first few compartments or boxes, and from time to time review the questions in the other boxes. The result is a reduction in the amount of time needed to study a subject.
Originally, LenMus exercises were not based on any particular learning methodology. Questions were selected just at random and easy questions were repeated annoyingly. Therefore, in version 4.1 I started to experiment with the idea of adding support for the Leitner methodology in a couple of exercises.
The first tested algorithm (LMA-1, Annex 1) was a direct implementation of Leitner method. I tested it with the intervals identification exercise (theory). The results were quite bad because the Leitner method is suited for problem spaces where you have to memorize the answer to a question. But in most music theory exercises, the objective is not to memorize an answer but to learn a concept (i.e. “3rd major interval”) and quickly identify examples of the concept that can have different representations in a music score.
In the original Leitner method for learning facts, a correct answer means that you know the fact to learn. But when you are studying concepts, a correct answer means that the student always succeed in recognizing an example of the concept. So, presenting just one example of the concept and recognizing it is not enough to conclude that the concept is learn. In these cases, the direct implementation of Leitner method leads to a lot of irrelevant repeated questions: for instance all possible 3rd major intervals!
By considering how a human teacher could determine if a student has learn a concept (i.e. 3rd major interval), I concluded that the program should consider that the concept is learn not when all possible 3rd major intervals has been displayed and the student has successfully recognized all them but when a certain number of 3rd major intervals has been presented and successfully recognized without failures.
Therefore, to adapt the Leitner method for learning concepts instead of facts, I kept the idea of demoting a question if it is failed, but I introduced a new criteria for promoting a question: the consecutive number of samples of a concept that was successfully recognized by the student (RT, Repetition Threshold). The idea is to assume that a concept has been learn when the student has successfully recognized RT samples of the concept without a failure. The modified algorithm (LMA-2) is presented in Annex 2. This is the current algorithm used in LenMus.
I would be more than happy if a music teacher would like to join me to make LenMus a great tool for music students and teachers. It is necessary to continue defining and reviewing all pedagogical issues of the LenMus program: syllabus, exercises, Leitner method issues, etc. Programming and managing the project takes most of my time and I can not do more!
All LenMus exercises have at least two operation modes: ‘exam’ and ‘quiz’.
In version 4.1, as a proof of concept, I started to implement the Leitner methodology. As a consequence, in those exercises adapted for using the Leitner methodology, two additional operation modes area available: ‘learning’ and ‘practising’.
A concept is studied along several course grades. In each grade, the concept is studied with more detail. Also, for each grade, there can be difficulty levels.
Therefore, the first step is to analyse and define the course grades. This is has to be done in any case, even if Leitner method is not used, and its is a consequence of the chosen syllabus. It is also a requirement for defining exercise programming specifications.
The additional task to perform, when Leitner method is going to be used, is to group exercise settings to define the difficulty levels for each grade. And then, the flashcard decks are defined, by grouping questions by grade and difficulty level. As an example, in the following section the process for defining the question desks for the interval exercises is examined in detail.
The following terminology will be used:
I decided to try an abstract implementation of the modified Leitner method so that the same code could be used by all exercises. A problem space is defined by a vector of ‘flashcards’ (question items) containing all data about questions, user performance and current box. So each question is characterized by the following information:
question index (0..n)
current box
times asked in current session
times success in current session
times asked global
times success global
With previous definition, each question is just a number (the question index). Therefore, the Leitner method implementation knows nothing about each question content: it just deals with question indexes. It is responsibility of each exercise to define the real questions and to assign induces to them. Exercise will create and pass the problem space vector to the Leitner manager. And it will be responsibility of each exercise to serialize data and relate it to a specific user.
The first step is to analyses and define the requirements for course grades. The interval identification exercise will organized in four levels to match the requirements of most common syllabus:
Therefore, for each level there must be at least one deck of questions.
The second step is to define the exercise setting options that will be available for each level, and group these settings to define ‘difficulty levels’. The exercise has settings to choose clefs, key signatures, and maximum number of ledger lines.
For level 0 the available settings doesn’t modify the possible questions to ask. Therefore, for level 0 there will be only one deck, D0, containing all possible questions for these level: the name (just the number) of all intervals.
For the other levels, the selection of a clef doesn’t change the set of questions, but the selection of a key signature significantly changes the set of possible questions. Therefore, it was decided to create a deck for each key signature. This leads to the need to define the following decks:
Deck D1k: No accidentals. Perfect, major and minor intervals in k key signature. Deck D2k: One accidental. Augmented and diminished intervals in k key signature. Deck D3k: Two accidentals. Double augmented / diminished intervals in k key signature.
Now, the set of questions to use for each exercise level will be created by using the following decks:
Set for level 0: Deck D0 Set for level 1: Set 0 + decks D1k, for k = all selected key signatures Set for level 2: Set 1 + decks D2k, k = all selected key signatures Set for level 3: Set 2 + decks D3k, k = all selected key signatures
The repetition intervals table is taken from the one proposed by K.Biedalak, J.Murakowski and P.Wozniak in article “Using SuperMemo without a computer”, available at http://www.supermemo.com/articles/paper.htm. According to this article, this table is based on studies on how human mind ‘forgets’ factual information.
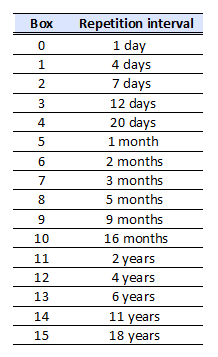
Except for box 1, this table use a factor of 1.7 to increase subsequent intervals.
In order to provide the student with some indicators of his/her long term acquired knowledge it was necessary to study and define a suitable way of doing it. Many indicators could be proposed but the approach followed has been pragmatic, oriented to the main issue that usually worry the student: his/her probabilities to pass an examination. For this purpose, three ‘achieved retention level’ indicators has been defined: short, medium and long term indicators. They attempt to provide a quantitative evaluation for the student preparation for not failing any question in an examination to be taken at three time points: in the short term (i.e., in 20 days), at the end of the academic year (i.e., in 9 months) or in long term (in a few years).
For defining these ‘achieved retention level’ indicators it was taken into account that each box 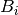 represents a more consolidated level of knowledge than the preceding box
represents a more consolidated level of knowledge than the preceding box 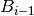 . Therefore, a weighting factor
. Therefore, a weighting factor 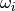 has been assigned to each box, and the boxes have been grouped into three sets:
has been assigned to each box, and the boxes have been grouped into three sets:
The split points are shown in following table:
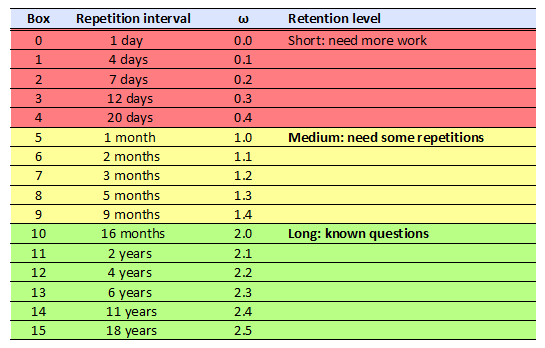
To have great chances of passing an examination to be taken in 20 days it should be ensured that all questions are in box 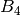 or above it. Therefore, the indicator for ‘short term achievement’ should display 100% when all questions are in box or above it; it should mark 0% when all questions are in box
or above it. Therefore, the indicator for ‘short term achievement’ should display 100% when all questions are in box or above it; it should mark 0% when all questions are in box 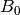 ; and should advance smoothly as questions are promoted between boxes to . To satisfy these requirements I have tried different formulas. After some simulations, I finally choose a formula derived as follows:
; and should advance smoothly as questions are promoted between boxes to . To satisfy these requirements I have tried different formulas. After some simulations, I finally choose a formula derived as follows:
Let’s name 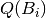 total number of questions in box , and
total number of questions in box , and 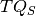 the total number of questions in all boxes of set ‘Short’. That is:
the total number of questions in all boxes of set ‘Short’. That is:
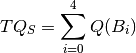
Analogously, for sets ‘Medium’ and ‘Long’ we define:
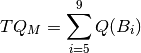
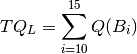
and the total number of questions in all boxes:
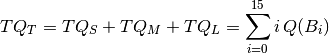
Let’s also define a ‘score’ 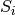 for each box just by applying the weight factor to the number of questions in that box:
for each box just by applying the weight factor to the number of questions in that box:
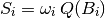
Analogously, we define the total score for each set of boxes, as follows:
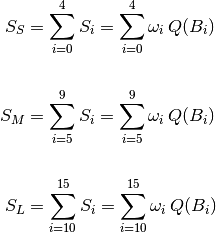
With these definitions, the ‘short term achievement’ indicator, 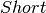 , as the ratio between current score and maximum score, but computing questions in medium an long term boxes as if all them were placed in box :
, as the ratio between current score and maximum score, but computing questions in medium an long term boxes as if all them were placed in box :
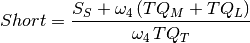
Analogously, we define indicators 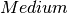 and
and 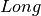 for medium and long term achievement:
for medium and long term achievement:
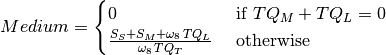
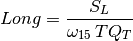
Global progress is displayed:
If 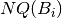 is the number of questions in box , the percentage of questions on each group is computed
is the number of questions in box , the percentage of questions on each group is computed
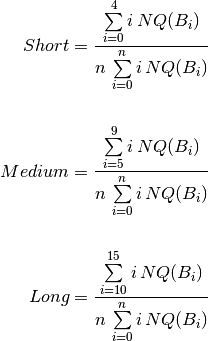
Also, a global assessment is computed by assigning a weight factor to each box . Taking into account that each box represents a more consolidated level of knowledge than the preceding box , a weighting factor can be assigned to each group of boxes, to get a score. Unlearned questions, that is questions in group (boxes to ) count as 0 points per question. Questions in group (boxes 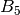 to
to 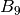 ) count as 1 point per question. And questions in group (boxes
) count as 1 point per question. And questions in group (boxes 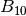 to
to 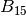 ) count as 2 points per question.
) count as 2 points per question.
If 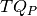 ,
, 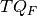 and
and 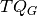 denotes the total number of questions in groups , and , respectively, the the student score is computed as follows:
denotes the total number of questions in groups , and , respectively, the the student score is computed as follows:
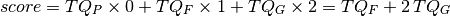
The maximum score is when all questions are in the group:
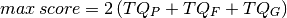
Therefore, a global assessment can be, simply, the ratio current score / maximum score:
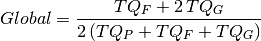
As no performance data is saved, there is no use in displaying the same information than in learning mode. The only useful information for the student is the same than in ‘exam’ mode:
(to be continued...)
Sorry, no more time for more details
ProblemSpace
* The set of questions for an exercise and level
CountersCtrol
| * The window to display user performance statistics
|
+--- LeitnerCounters (for 'learning' mode)
|
+--- PractiseCounters (for 'practise' mode)
|
+--- QuizCounters (for 'exam' and 'quiz' modes)
ProblemManager
| * Chooses a question and takes note of right/wrong user answer
| * Load/Saves/Updates the problem space.
| * Keep statistics about right/wrong answers
| * Owns:
| * ProblemSpace
|
+--- LeitnerManager
| * A problem manager that chooses questions based on the Leitner
| system, that is, it adapts questions priorities to user needs
| based on success/failures
| * Used for 'learning' and 'practise' modes.
|
+--- QuizManager
* A problem manager that generates questions at random.
* Used for 'exam' and 'quiz' modes.
ExerciseCtrol
* Chooses a ProblemManager suitable for the exercise mode (create_problem_manager() method)
* Chooses a CountersCtrol suitable for the exercise mode
* Owns:
* ProblemManager
* CountersCtrol
The first tested algorithm was a direct implementation of Leitner method:
1. Prepare set of questions that need repetition (Set0):
* Explore all questions and move to Set0 all those questions whose
scheduled time is <= Today or are in box 0
2. Start exercise:
* Shuffle Set0 (random ordering).
* While questions in Set0:
* For iQ=1 until iQ=num questions in Set0
* Take question iQ and ask it
* If Success mark it to be promoted, and schedule it for
repetition at Current date plus Interval Repetition for
the box in which the question is classified. Else, if
answer was wrong, move question to box 0.
* End of For loop
* At this point a full round of scheduled questions has taken
place: Remove from Set0 all questions marked as 'to be
promoted'.
* End of While loop
3. At this point, a successful round of all questions has been
made:
* Display message informing about exercise completion for today
and about next repetition schedule. If student would like to
continue practising must move to 'Practising Mode'.
After some initial testing with algorithm LMA-1 it didn’t produced satisfactory results. This was because Leitner method is best suited for problem spaces where you have to memorize the answer to a question. But in most LenMus exercises, the objective is not to memorize some answer but to learn a concept (i.e. “3rd major interval”) and quickly identify examples of the concept that can have different representations in a music score.
To deal with this, previous algorithm LMA-1 was modified to introduce a new factor: the consecutive number of samples of a concept that was successfully recognized by the student (RT, Repetition Threshold). The idea is to assume that a concept has been learn when the student has successfully recognized RT samples of the concept. By introducing this factor in algorithm 1 we get algorithm 2:
1. Prepare set of questions that need repetition (Set0):
* Explore all questions and move to Set0 all those questions whose
scheduled time is <= Today or are in box 0
2. Start exercise:
* Shuffle Set0 (random ordering).
* While questions in Set0:
* For iQ=1 until iQ=num questions in Set0
* Take question iQ and ask it
* If Success, increment the question repetitions counter.
Else reset the question repetitions counter and move
question to box 0.
* If the question repetitions counter is grater than the
Repetition Threshold (RT) mark the question to be promoted,
and schedule it for repetition at Current date plus
Interval Repetition for the box in which the question
is classified.
* End of For loop
* At this point a full round of scheduled questions has taken
place: Remove from Set0 all questions marked as 'to be
promoted'.
* End of While loop
3. At this point, a successful round of all questions has been
made:
* Display message informing about exercise completion for today
and about next repetition schedule. If student would like to
continue practising must move to 'Practising Mode'.
If user would like to continue practising, the questions should be chosen at random but with a non-uniform probability distribution, giving more weight to questions in lower boxes. In any case, questions are never promoted nor demoted.
The first step for defining the algorithm has been to consider the minimum number of times each question has been studied. Questions in box 0 are not yet studied. So if we name 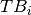 the number of times a question in box has been studied, for box 0 it is
the number of times a question in box has been studied, for box 0 it is 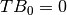 . Questions in box 1 have been studied at least 1 time, so
. Questions in box 1 have been studied at least 1 time, so 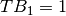 . Questions in box 2 have been studied at least 2 times (once to promote to box 1 and a second one to promote to box 2), therefore
. Questions in box 2 have been studied at least 2 times (once to promote to box 1 and a second one to promote to box 2), therefore 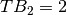 . And so on. Therefore, the general formula is:
. And so on. Therefore, the general formula is:
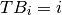
The second step was to assign a probability to each box in inverse proportion to the number of times a question in that box has been studied:
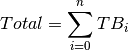
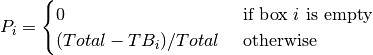
In previous description, it is assumed that all boxes have questions. But in practise, there could be empty boxes. To take this into account it is enough to exclude those boxes from computations. This can be achieved by changing the definition of as follows:
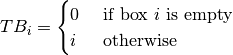
Then the algorithm to select a question in practise mode is as follows: